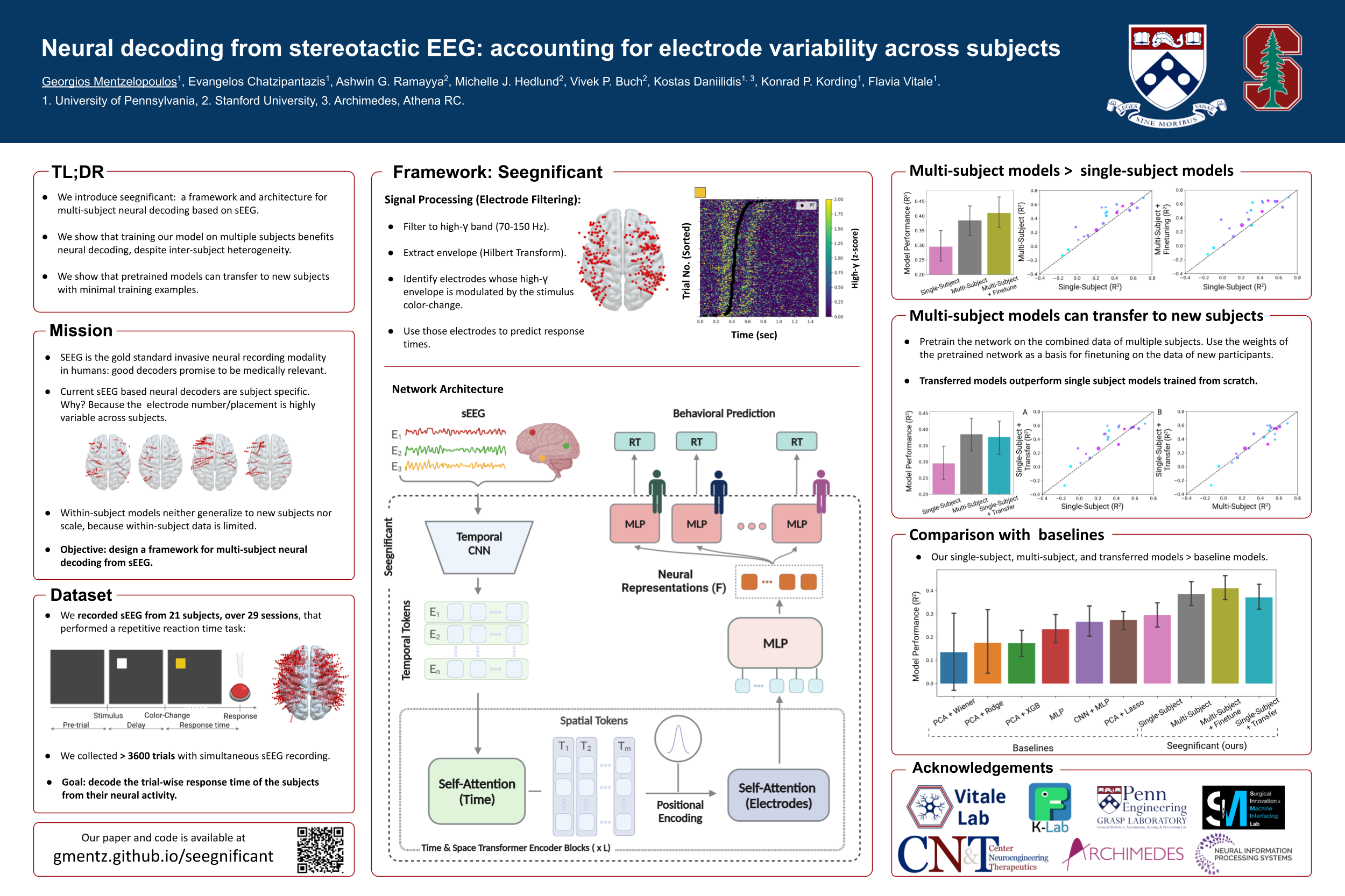
Neural decoding from stereotactic EEG: accounting for electrode variability across subjects
1 University of Pennsylvania
![]() 2 Stanford University
2 Stanford University
 3 Archimedes, Athena RC
3 Archimedes, Athena RC
![]()
 Paper
Paper
 Code
Code
 Poster
Poster
Published at the 38th Conference on Neural Information Processing Systems (NeurIPS 2024).
Abstract
Deep learning based neural decoding from stereotactic electroencephalography (sEEG) would likely benefit from scaling up both dataset and model size. To achieve this, combining data across multiple subjects is crucial. However, in sEEG cohorts, each subject has a variable number of electrodes placed at distinct locations in their brain, solely based on clinical needs. Such heterogeneity in electrode number/placement poses a significant challenge for data integration, since there is no clear correspondence of the neural activity recorded at distinct sites between individuals.
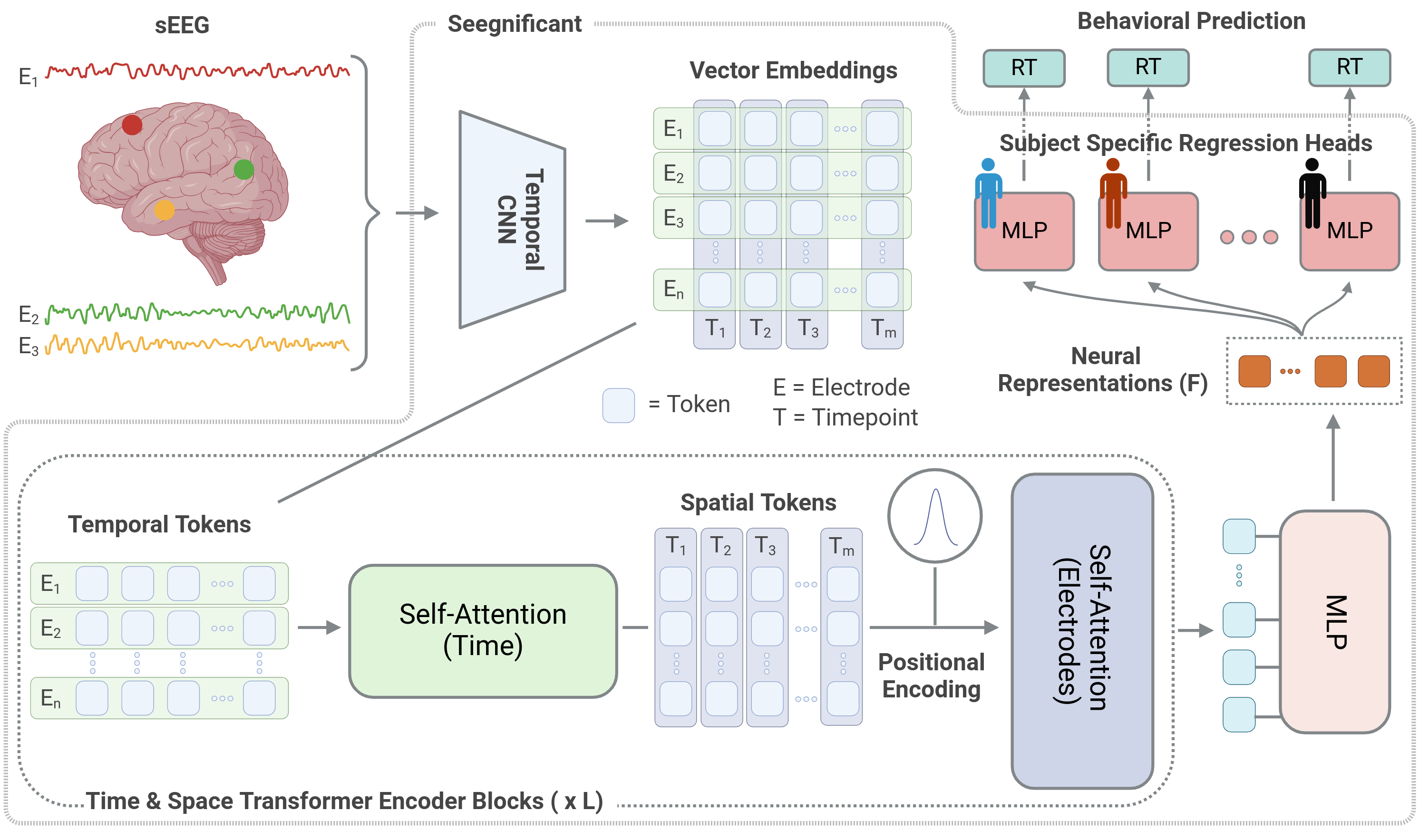
Here we introduce seegnificant: a training framework and architecture that can be used to decode behavior across subjects using sEEG data. We tokenize the neural activity within electrodes using convolutions and extract long-term temporal dependencies between tokens using self-attention in the time dimension. The 3D location of each electrode is then mixed with the tokens, followed by another self-attention in the electrode dimension to extract effective spatiotemporal neural representations. Subject-specific heads are then used for downstream decoding tasks.
Using this approach, we construct a multi-subject model trained on the combined data from 21 subjects performing a behavioral task. We demonstrate that our model is able to decode the trial-wise response time of the subjects during the behavioral task solely from neural data. We also show that the neural representations learned by pretraining our model across individuals can be transferred in a few-shot manner to new subjects. This work introduces a scalable approach towards sEEG data integration for multi-subject model training, paving the way for cross-subject generalization for sEEG decoding.
Dataset
Neural Recordings. We obtained neural recordings from 21 subjects that were implanted with sEEG electrodes as part of their medical care for medical refractory epilepsy. Based on clinical needs alone, each subject was implanted with a variable number of electrodes at district locations in their brain (see Fig. 1). Subjects were mixed in terms of sex (8 male, 13 female), age (ranging from 16-57 years old), and ethnic background.
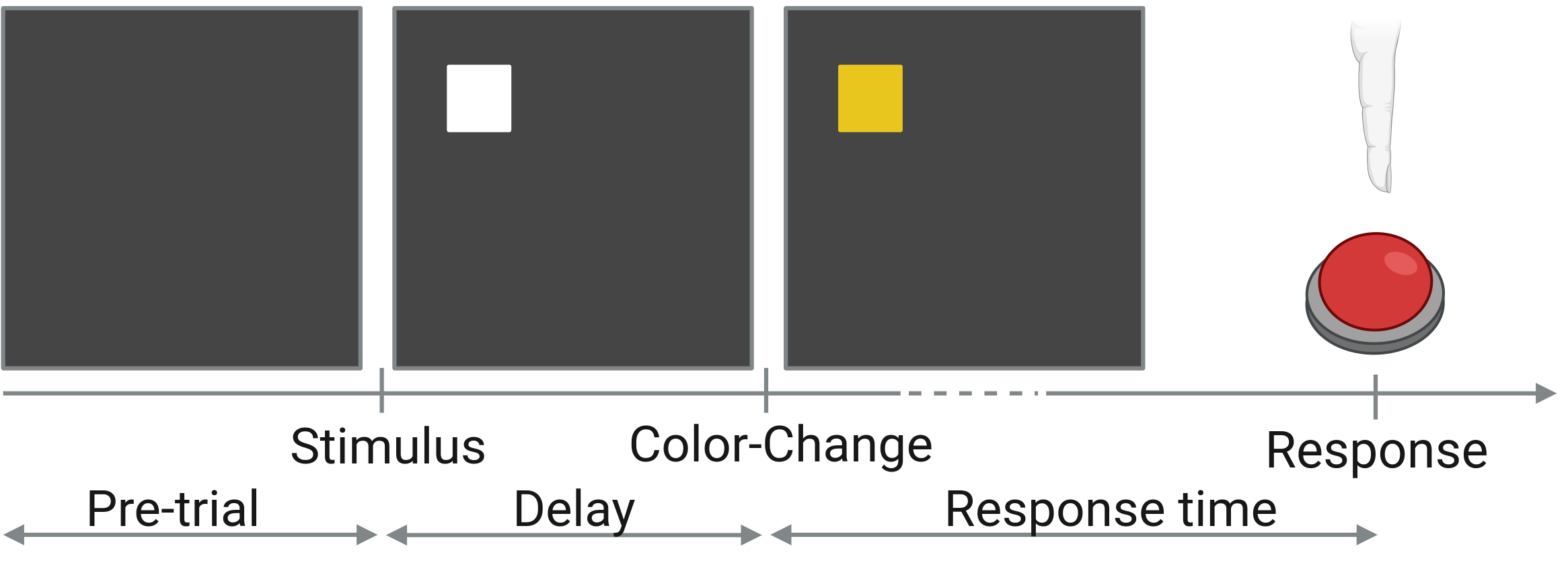
Behavioral Task. Subjects completed the color-change detection task (a repetitive, reaction time task) while their sEEG was simultaneously recorded (see Fig. 2). In each trial of the task, a visual stimulus was presented. After a variable delay, the stimulus changed color. At that time, the subject responded by pressing a button as fast as they could.
Mission
Our goal was to build a multi-subject model capable of decoding the trial-wise response time of subject using their sEEG.
Challenges.
- Variability of electrode number/placement across subjects: Subjects were implanted with sEEG as part of their medical care, so the number and placement of electrodes was determined solely based on clinical needs. Therefore, there is no clear correspondence between the neural activity recorded between individuals.
- Limited amount of per-subject data: Due to clinical circumstances, each subject completed only a few behavioral trials ($\sim$ 175 trials per subject). This is a barrier to scaling up, since neural networks require a lot of data to generalize effectively.
- Variability in behavioral outcomes across subjects: The response time statistics of each subject are unique (how fast they respond on average), posing a significant challenge to integrating data across subjects.
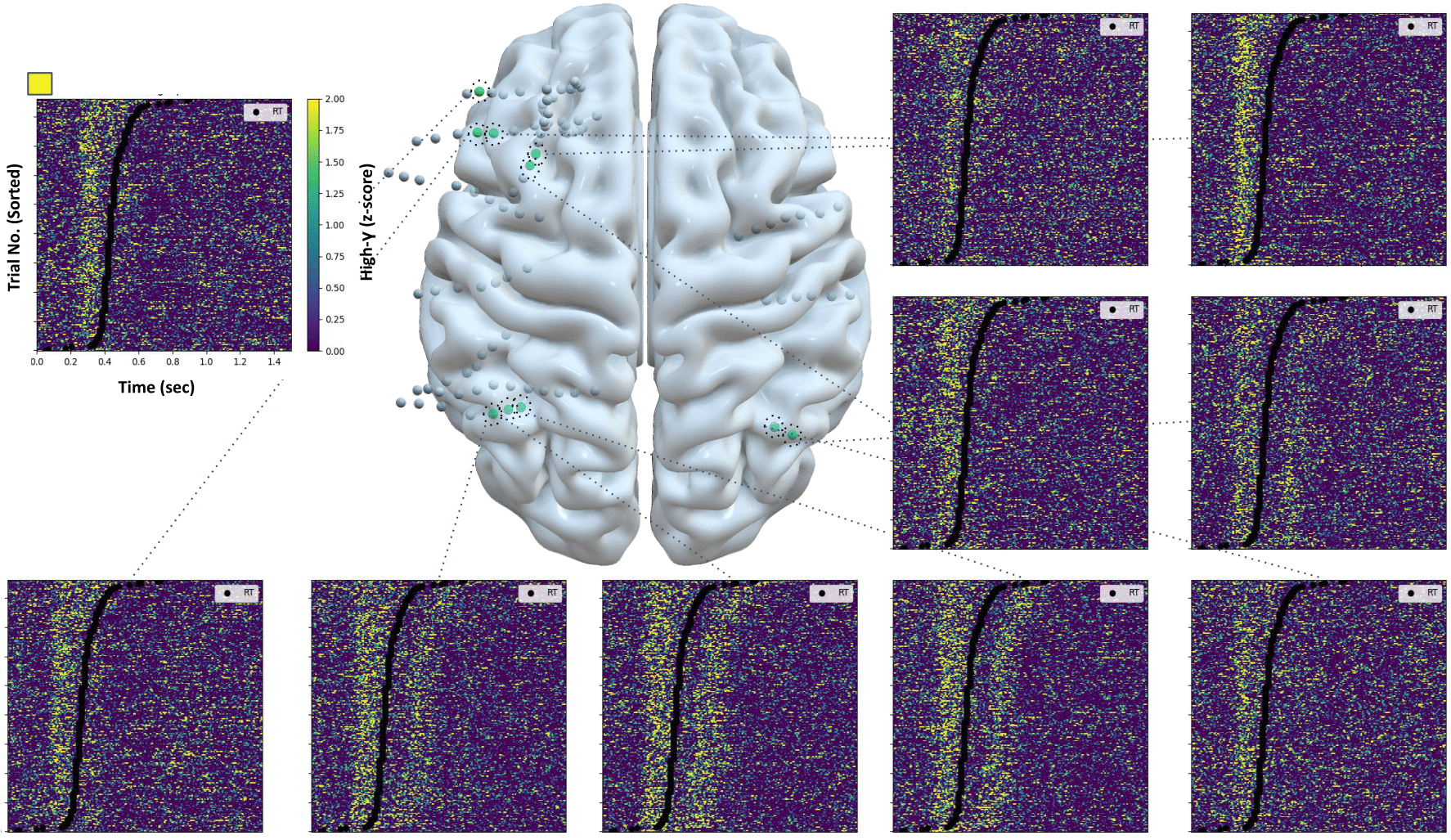
Signal processing
Motivated by the lack of correspondence between the neural activity recorded across subjects, we sought to identify the subset of electrodes that respond to the stimulus color-change during the behavioral task. We identified those electrodes using methods developed by Paraskevopoulou et al. (2021) based on each electrode's high-gamma power (narrowband neural activity with frequency content between 70-150 Hz). This procedure isolated electrodes that monitor neural populations that are relevant to the task, and therefore are likely to contain information about the response time of the subject for each trial (Fig. 3). The electrical activity of those electrodes was then used for response time decoding.
Network architecture
Having identified electrodes whose neural activity contains information about each trial's response time, our problem reduced to building a map from the multivariate timeseries of neural activity of each trial to the response time of the same trial.
We built this map using the network show in Fig. 4, composed of the following building blocks:
- Temporal CNN (Tokenizer): We use a CNN that operates on each electrode separately to tokenize the neural activity of each electrode.
- Self-attention in time: Having tokenized the neural activity, we process the tokens with self-attention [Vaswani et al. (2017)] in the time dimension, to capture long-term dependencies between timepoints.
- Spatial positional encoding: Using MNI coordinates, we add information about each electrode's location in the brain to the tokens.
- Self-attention in space: We then process the tokens with another self-attention [Vaswani et al. (2017)] in the electrode dimension, to capture long-range dependencies of the neural activity across electrodes.
- Compression: The tokens are then projected to a lower dimensional representation using an MLP.
- Subject specific regression heads: The representations are then projected to a single value, which is the response time estimate of a given trial, using MLPs that are unique for each subject.
Results: single- and multi-subject model training
Training single subject models. To test whether our modeling approach would be able to decode the trial-wise response time from sEEG data, we first trained a separate model for each subject. Across the 21 single-subject models, the average test set $R^2$ was 0.30 ± 0.05 (mean ± sem)
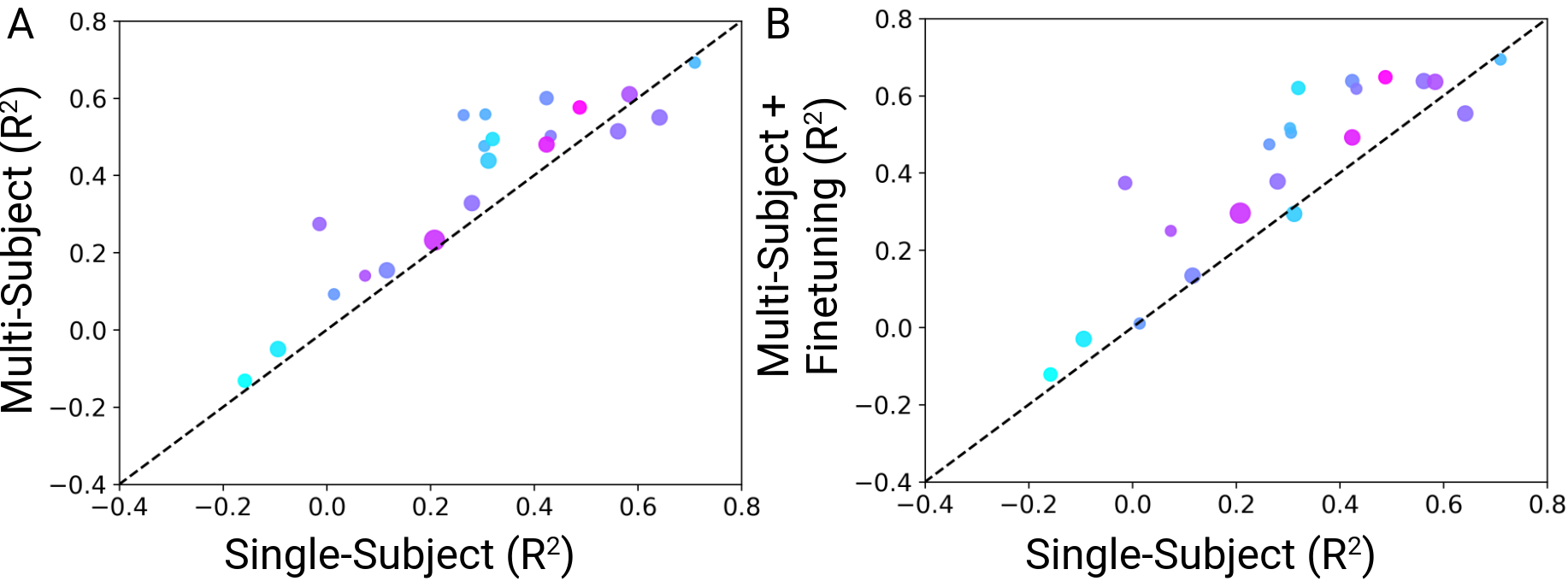
Training a multi-subject model. To investigate whether training on more data, despite the heterogeneity, would improve decoding performance, we trained a multi-subject model on the combined data of all subjects. The average per-subject test set $R^2$ for the multi-subject model was 0.39 $\pm$ 0.05 (mean $\pm$ sem). The multi-subject training approach boosted decoding performance by $\Delta R^{2}$ = 0.09, on average, compared to training on single subjects (Fig. 5A).
Finetuning the multi-subject model to single subjects. We then tested whether finetuning the multi-subject model to individual subjects would further boost the performance gains. The multi-subject model, finetuned to each subject achieved an average per-subject test set $R^2$ score of 0.41 $\pm$ 0.05 . Finetuning the multi-subject model to individual subjects boosted the performance gains by $\Delta R^{2}$ = 0.11, on average, compared to single subject models (Fig. 5B).
Results: transferring multi-subject models to new subjects
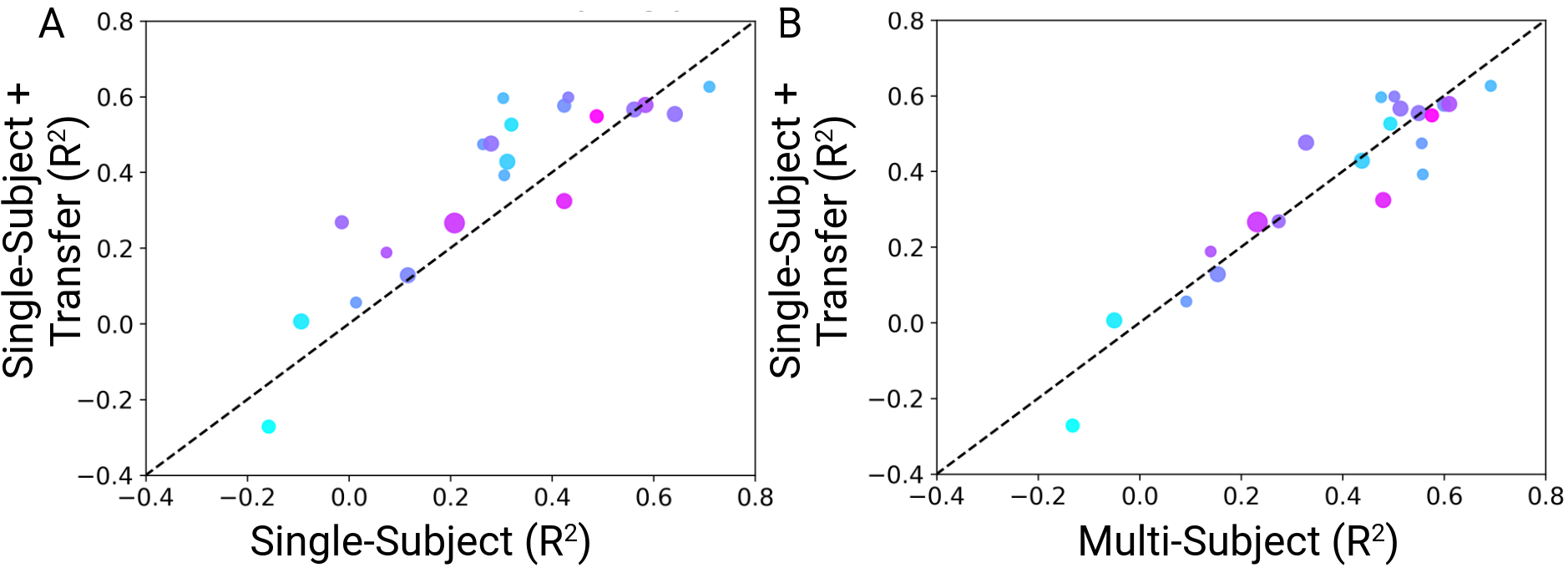
Transferring the multi-subject model to new subjects. We were interested in identifying whether the multi-subject models can efficiently be transferred to new subjects, unseen from the model during training. To test this, we employed a leave-one-out cross validation approach. We trained 21 models, each of which was trained on the combined data of all subjects but one. The weights of the pretrained models were then used as the basis for finetuning on the data of each left-out participant. Across subjects, the models trained on other subjects and transferred to a new one achieved an average test set $R^{2}$ of 0.38 $\pm$ 0.05 (mean $\pm$ sem). The transferred single-subject models showed a decoding performance increase $\Delta R^{2}$ = 0.08 compared to the single-subject models trained from scratch (Fig. 6A) and showed decoding performance similar to the multi-subject model (Fig. 6B).
Results: baseline comparisons
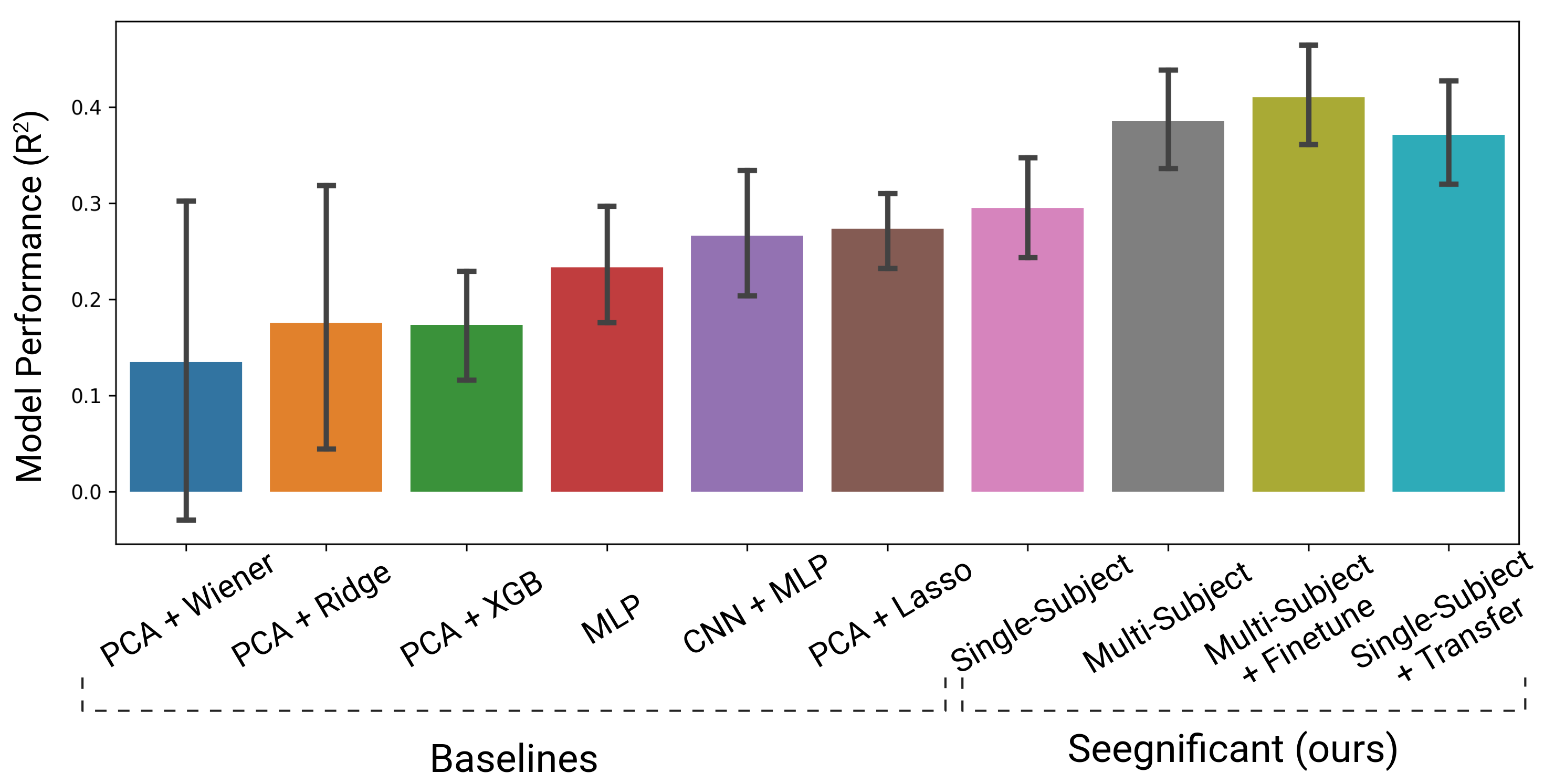
Last, we compared our modeling approach against other traditional and state-of-the art neural decoding approaches. Seegnificant outperformed all other approaches when trained on single subjects, multiple subjects, and when transferred (Fig. 7).
Citation
@inproceedings{mentzelopoulos2024neural,
author = {Mentzelopoulos, Georgios and Chatzipantazis, Evangelos and Ramayya, Ashwin and Hedlund, Michelle and Buch, Vivek and Daniilidis, Kostas and Kording, Konrad and Vitale, Flavia},
booktitle = {Advances in Neural Information Processing Systems},
editor = {A. Globerson and L. Mackey and D. Belgrave and A. Fan and U. Paquet and J. Tomczak and C. Zhang},
pages = {108600--108624},
publisher = {Curran Associates, Inc.},
title = {Neural decoding from stereotactic EEG: accounting for electrode variability across subjects},
url = {https://proceedings.neurips.cc/paper_files/paper/2024/file/c473b9c8897f50203fa23570687c6b30-Paper-Conference.pdf},
volume = {37},
year = {2024}
}